统计学方法早期自然语言处理研究中常用的方法,通过统计文本中词汇和语法结构的出现频率,来推断文本的含义和上下文关系。这种方法在文本分类、情感分析等领域有广泛应用。规则引擎方法基于语言学规则的自然语言处理方法,通过预定义的规则**来解析和生成自然语言。这种方法在句法分析、命名实体识别等任务中表现良好,但需要大量的语言学知识和规则设计。机器学习方法随着机器学习技术的发展,自然语言处理开始***采用基于机器学习的方法。这些方法通过训练模型来学习文本中的模式和规律,从而实现对自然语言的理解和处理。常见的机器学习方法包括支持向量机(SVM)、朴素贝叶斯(Naive Bayes)、决策树等。整合多部门服务,实现政策咨询、办事指南一站式解答。蜀山区定做智能客服量大从优

多角度可配置的统计分析智能监控系统截图我们设计的统计分析系统是一种统一的系统,可以监控不同的地区、渠道、品牌、业务、时间、话务员、客户类型等9个基本维度,同时也可以将上述基本维度进行复合,形成复合型监控维度,极大地扩展了现有监控技术。人工辅助在系统不能自动回复用户的问题时,将转人工处理。为此,我们研制并提供话务员操作系统,供话务员操作使用。该系统具有精确的语义检索能力,并且话务员可以在线编辑知识库,供其他话务员使用,或者经过审核后,供智能客服系统自动使用。肥东本地智能客服图片售后服务:退换货、投诉处理、使用指导等。

2022年底,随着ChatGPT等大语言模型的推出,自然语言处理的重点从自然语言理解转向了自然语言生成。文本预处理在自然语言处理中,文本预处理是一个重要的步骤,包括文本清洗(去除HTML标签、特殊字符等)、分词(将文本划分为**的词汇单元)、词性标注(确定每个词汇的词性)等。词嵌入词嵌入是将词汇转换为计算机可理解的向量表示的过程。常见的词嵌入技术包括Word2Vec、GloVe等。这些技术可以捕捉词汇之间的语义关系,使计算机能够理解词汇的深层含义。
该系统是一种点式或条式的知识管理系统,因此是一种细粒度的管理工具。这中细粒度的知识管理工具,使得大型企业更有效,更能从知识的运行中实时地掌握企业的运行状态,从而更有效地进行科学决策。例如,在客户的统计信息、热点业务统计分析、VIP统计信息等可以在极短的时间内获得。这是一般知识管理工具所不支持的。下表具体给出了该系统与其它主要知识管理工具的重要区别。语言应答智能应答系统首先对客户文字咨询进行预处理系统(包括咨询无关词语识别、敏感词识别等),然后在三个不同的层次上对客户咨询进行解析——语义文法层理解、词模层理解、关键词层理解。处理套餐变更、流量查询、故障报修等高频问题。

文本生成文本生成是指接收结构化表示的语义,以输出符合语法的、流畅的、与输入语义一致的自然语言文本,这自然语言处理中的另一个重要任务,它可以根据给定的输入(如关键词、句子结构等)生成新的文本。这可以用于各种应用,如机器翻译、文本摘要、对话系统等。早期基于规则的自然语言生成技术,在每个子任务上均采用了不同的语言学规则或领域知识,实现了从输入语义到输出文本的转换。自然语言处理技术的发展主要依赖于多种方法和技术,这些技术帮助计算机更好地理解和处理自然语言。通过智能客服,企业能够提高效率、降低成本,同时提升客户体验。肥东本地智能客服图片
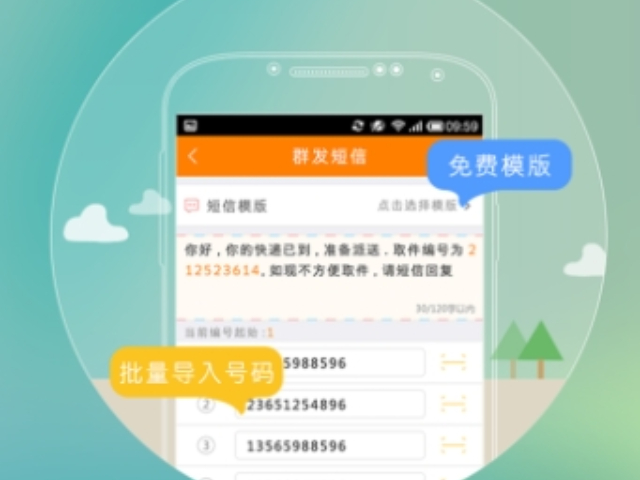
示例:用户输入“如何退货?”,智能客服可识别意图并引导至退货流程页面。蜀山区定做智能客服量大从优
针对这一问题,文献提出了基于图卷积神经网络(graph convolutional neuralnetwork,GCN)的文本分类方法,在图上对局部结构进行建模,提取节点依赖关系,更好地捕捉文本信息,成功地将卷积神经网络应用到了图结构上 [8]。长期以来, 自然语言处理任务主要采用监督学习范式, 即针对特定任务, 给定监督数据, 设计统计学习模型, 通过**小化损失函数来学习模型参数, 并在新数据上进行模型推断。随着深度神经网络的兴起, 传统的统计机器学习模型逐渐被神经网络模型所替代, 但仍然遵循监督学习的范式 [11]。蜀山区定做智能客服量大从优
安徽展星信息技术有限公司在同行业领域中,一直处在一个不断锐意进取,不断制造创新的市场高度,多年以来致力于发展富有创新价值理念的产品标准,在安徽省等地区的安全、防护中始终保持良好的商业口碑,成绩让我们喜悦,但不会让我们止步,残酷的市场磨炼了我们坚强不屈的意志,和谐温馨的工作环境,富有营养的公司土壤滋养着我们不断开拓创新,勇于进取的无限潜力,展星供应携手大家一起走向共同辉煌的未来,回首过去,我们不会因为取得了一点点成绩而沾沾自喜,相反的是面对竞争越来越激烈的市场氛围,我们更要明确自己的不足,做好迎接新挑战的准备,要不畏困难,激流勇进,以一个更崭新的精神面貌迎接大家,共同走向辉煌回来!